
[ad_1]
Whether we’re using Spotify, Amazon, Netflix or Instagram, we encounter algorithms that recommend content or products to us every day. In 2017 Netflix stated that its users discover around 80 percent of shows through algorithmic recommendations. But when I look at what this streaming platform offers me, I am often only moderately enthusiastic. For example, the series Tour de France: Unchained is a 98 percent match, even though I’m not interested in sports documentaries or cycling. And on Spotify, Amazon or Twitter (now X), I am continually puzzled by the content the algorithms show me.
Yet the moment I think I will need a new rain jacket, I receive advertisements for one. If I allow it, online companies will collect a wide variety of data, including my Web surfing behavior and location, which they use to offer me products. The systems involved are constantly improving. But how do they actually work?
Many connections can be used to generate recommendations. For example, I like to jog, so running shoes and sportswear suit me. But relationships between products also matter: a mobile phone case is related to a mobile phone, as are films in the same genre as one another or books by the same author. Finally, there can be connections between users. If I liked the Sherlock Holmes series as much as someone else, then I may like other content they enjoyed.
[Read more about AI algorithms]
For recommendation algorithms to examine these relationships, they need a lot of data. Therefore many providers, such as Netflix, Amazon and Spotify, ask users to rate content. But because this is not always done reliably, some algorithms access other information, too—for example, specific product descriptions and customer data, including age, gender and location.
With enough data, there are essentially two approaches to making recommendations. The first, “collaborative filtering,” is based on ratings by other users with similar behavior. The second is content-based: users receive recommendations for items similar to what they have positively reviewed previously. Both have advantages and disadvantages and can be combined for better results.
Collaborative Filtering
Let’s say you want to build a mini Netflix platform with six different movies and five users. The users have already watched and rated some of these films on a scale from one to five (five if they loved it; one if they hated it). You can now use a collaborative filter system to decide which films to recommend. You write down the ratings in a table with the columns corresponding to the films and the rows to the users. In mathematics, this listlike structure with numerical entries is called a matrix.
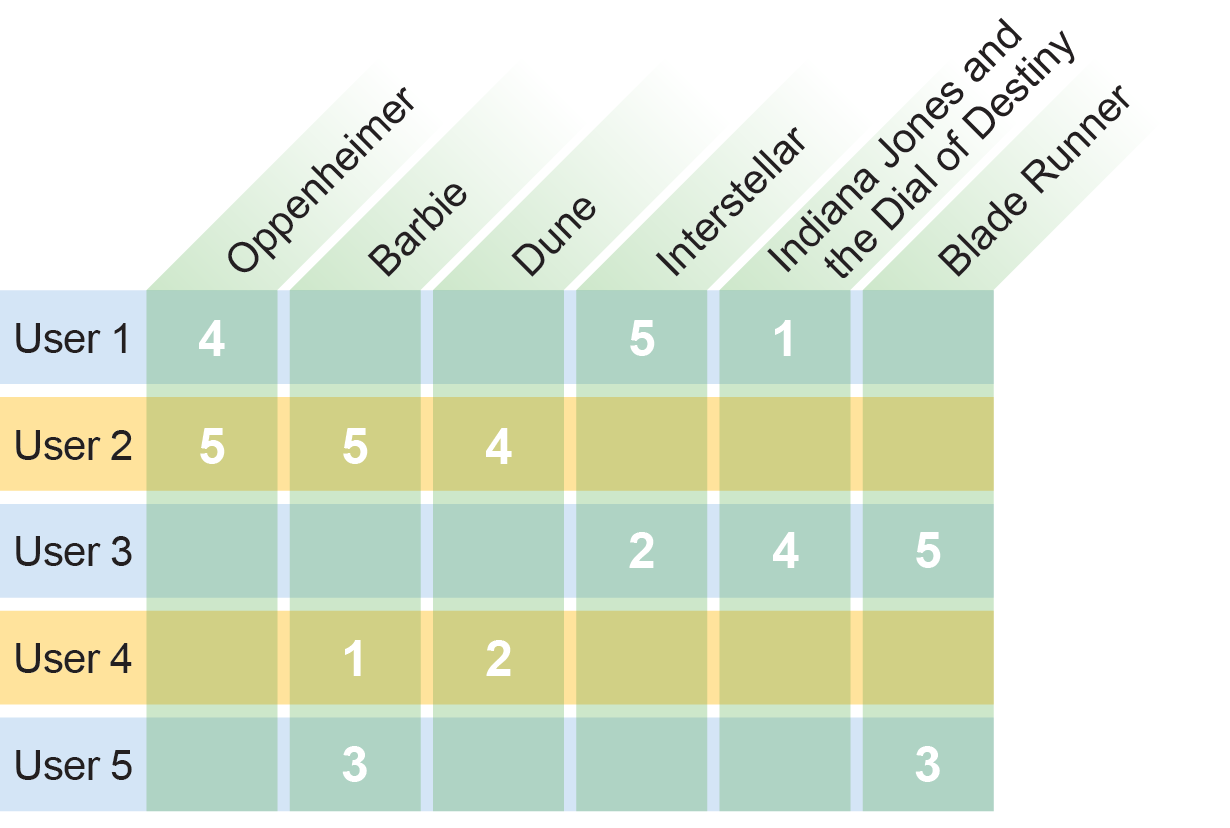
Because not every person has seen all six films, many fields are empty. This is where recommendation algorithms struggle most: they have to draw the most accurate conclusions possible based on sparse data. For example, to give User 1 a recommendation, you could try to pick another user with similar taste. But how do you determine this similarity? To define how far or close the preferences of two people may be, you can fall back on the mathematical discipline of measure theory.
In everyday life, there are several ways to specify distance. For example, you can calculate the distance between two cities that are close together by drawing a straight line between them on a map and measuring its length. To measure longer distances, you can draw a thread around a globe, such that the shortest route is a curve—after all, Earth is not flat. Or to travel from one place to another, you may need to consider streets and roads to calculate the walking distance.
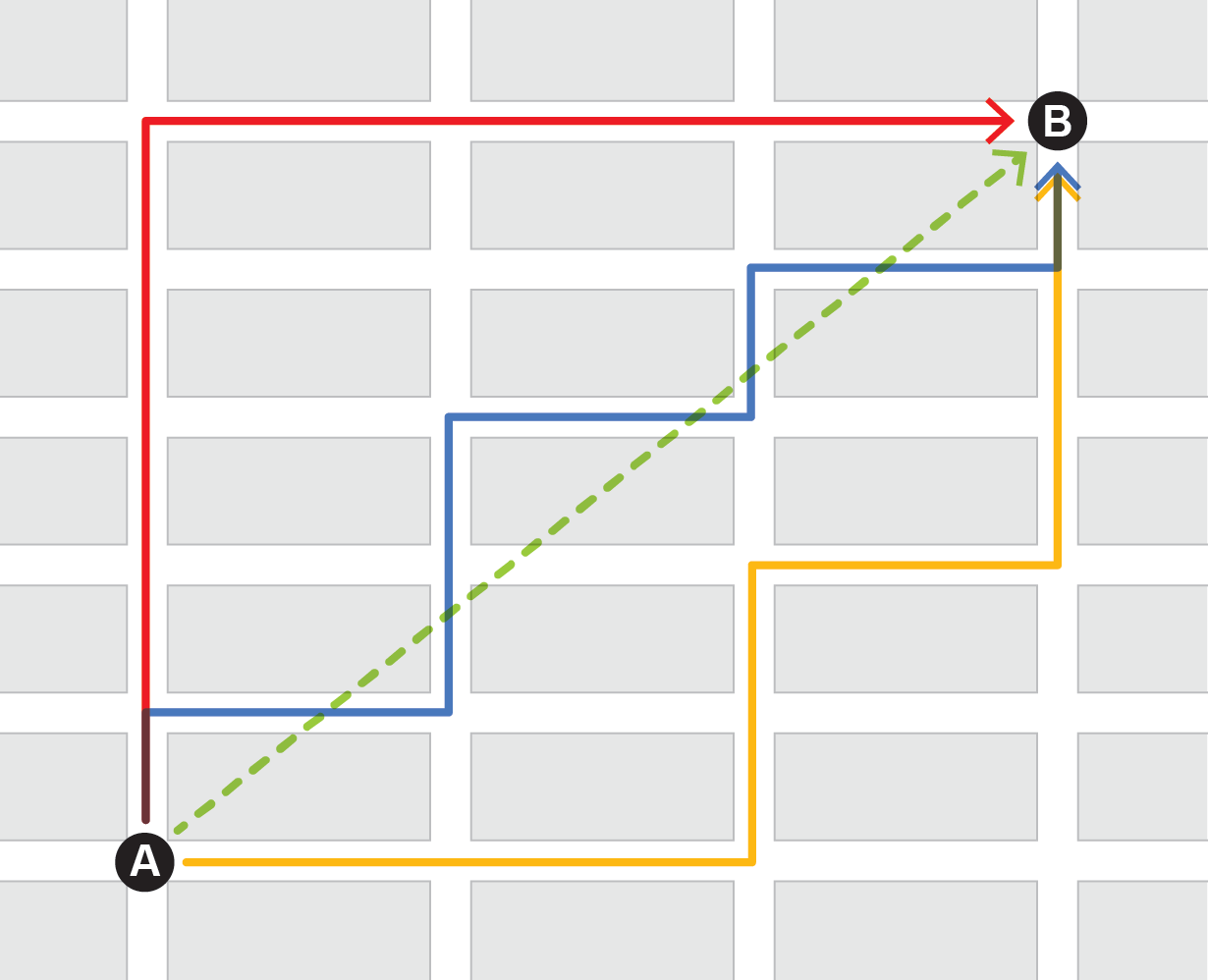
All sorts of metrics and similarity measures can be defined for a wide variety of purposes, including the similarity of genes or words. For your mini Netflix system, you could assign each user a list of numbers with their corresponding ratings (called a vector). In that way, you have five straight lines, one for each user, located in a six-dimensional space (with one dimension for each film). To determine the similarity of two vectors is to determine the angle they make with each other. This quantity is called cosine similarity.
.png)
In the example above, User 1 and User 2, as well as User 1 and User 3, can be compared because they rated some of the same films. User 1 and User 2 both rated Oppenheimer well. User 1 and User 3, on the other hand, came up with different results for Interstellar and Indiana Jones. To calculate the angle between two vectors, you multiply them together using the scalar product and then divide by the two vector lengths. Doing this for the above example shows that the angle between User 1 and User 2 is smaller than that between User 1 and User 3. In short, User 1 and User 2 seem to have more similar taste than User 1 and User 3. Because User 2 liked Barbie and User 1 hasn’t seen this film yet, you can suggest it to User 1.
Of course, when Netflix does this, there are far more users with similar tastes. Therefore, recommendations for an individual incorporate data from multiple people.
The Problem of Sparse Data
The most serious disadvantage of collaborative filter systems is insufficient data. That’s why Netflix often asks you to rate content you have already seen when you register. But even that approach has its pitfalls: just because I liked Oppenheimer does not mean I like all historical films, as may be the case for another Oppenheimer fan. In addition, some platforms use other data—such as age, gender or online behavior—to filter for similar interests. For example, some providers track how long users look at certain content or the other websites people visit.
This information results in an immense, ever changing matrix that grows with each new user or product. For optimal results, you have to constantly reevaluate the matrix. This task pushes the computing capacity limits even of large companies, such as Netflix and Amazon.
To spot patterns in this massive amount of data, companies use common methods from linear algebra, such as singular value decomposition or principal component analysis. The idea is to express the matrix as a product of simpler matrices—similar to the prime factorization of a number. The simpler matrices also contain information about user preferences, which is more easily accessible. With this approach, one can approximate nonessential information corresponding to small numerical values in the matrices by zero. Multiplying the approximated simple matrices back together yields a new matrix that is similar to the original but has a much simpler shape. A computer can better process it to issue recommendations.
Artificial intelligence models are increasingly used to process these data. Self-learning algorithms train to recognize patterns in the data so they, too, can predict what content a person might like. Companies often couple such systems with a technique called reinforcement learning: models constantly evolve through user feedback. For example, if the new Barbie movie is suggested to you, but you rate it poorly, the system learns from that to give you better suggestions in the future.
Content-Based Recommendations
Instead of just linking users to each other, you can also link products with other products. Amazon introduced such a system in 2003. To build a mini Netflix platform on this principle, you would reverse your table: the rows would correspond to the films and columns would correspond to the users. To add a missing rating—for example, “How will User 1 like Barbie?”,—look for similar films. For instance, if Oppenheimer and Dune were rated similarly to Barbie by other users, this content could be considered similar.
Amazon has found success with this system and continued to develop it. The relationship between products is central: running shoes are often associated with sportswear and water bottles, for instance. Combining this with other approaches leads to even more powerful predictions on the website.
While the collaborative approach relies on a lot of user data, content-based recommendations focus on the products being recommended. One can categorize movies by genre, directors, actors, length, and so on. This step is partially automated. By comparing a user’s preferences for relevant categories, recommendations can quickly be made. If a person sees the science fiction film Interstellar and then watches Barbie, co-starring actor Ryan Gosling, a content-based system might recommend Blade Runner 2049, a science-fiction film with Gosling. You can also use the cosine similarity here to compare content you have already seen with other products.
The advantage of this method is that you don’t need to explicitly rate a user. It is more important to properly characterize the products—a task that algorithms can take over.
Most recommendation algorithms now use hybrid approaches composed of collaborative and content-based systems. Netflix makes recommendations based on user behavior and similarity to other users, but it also takes into account preferences in terms of genre, actors, year of release and other attributes. Additionally, the platform evaluates what time you prefer to use it, how long you like to do so and which device you employ. But “the recommendations system does not include demographic information (such as age or gender) as part of the decision making process,” Netflix has stated.
How Transparent Should These Systems Be?
Recommendation algorithms are at the heart of many social media platforms—so it’s no surprise that companies want to keep them under wraps. The Chinese video portal TikTok is so popular mainly because it is very good at suggesting interesting content to its users. In March 2023 Twitter, now called X, publicized its recommendation algorithm on GitHub, along with an explanation of how the system works: for content to appear in a person’s timeline, the best tweets from various “recommendation sources” are first collected, and an AI model then evaluates them. Tweets from blocked people or those that have already been seen are filtered out.
But publishing the source code of a recommendation algorithm does not really contribute to the processes’ transparency, wrote IT developer Thomas Dimson, who led the design of Instagram’s original rating algorithm, in an article on the now defunct tech news site Future. “They have billions of weights that interact in subtle ways to make a final prediction; looking at them is like hoping to understand psychology by examining individual brain cells,” Dimson argues.
Making algorithms completely transparent could create other problems, however. In 2006, for example, Netflix offered $1 million to the developers who submitted the best possible recommendation algorithms. The streaming service provided training data with 100,480,507 ratings that 480,189 users had submitted for 17,770 pieces of content. In 2008, although the data were anonymized, two researchers at the University of Texas at Austin were able to identify some users based on their ratings on the film database IMDb.
That’s why Meta, the company behind Facebook and Instagram, is taking a different approach to transparency by explaining why certain content appears. Meta announced in June 2023 that it would use huge AI models, “larger than even the biggest language models used today,” for its recommendations. It also credits its use of AI models for a 24 percent increase in time spent on Instagram in the first quarter of 2023.
Given all the advances in AI, and in language models in particular, the precision of recommendation algorithms will most likely improve in the future. As the size of the models increases, however, transparency decreases—and it remains unclear which user-related data an algorithm uses. Not everyone is impressed by current advances. Meta, wrote journalist Devin Coldewey on TechCrunch, wants to “watch over my shoulder as I skim the web looking for a new raincoat and act like it’s a feat of advanced artificial intelligence when they serve me raincoat ads the next day.”
Indeed, recommendation algorithms help explain why so many of us feel like our smartphones spy on us. If you talk to someone about a rain jacket, and a moment later, that item appears on Instagram or Facebook, it’s not because you’re being recorded. Instead Meta is analyzing your contacts, your location and your online behavior very precisely. The result is a sophisticated recommendation, without any illegal wiretapping involved.
This article originally appeared in Spektrum der Wissenschaft and was reproduced with permission.
[ad_2]